










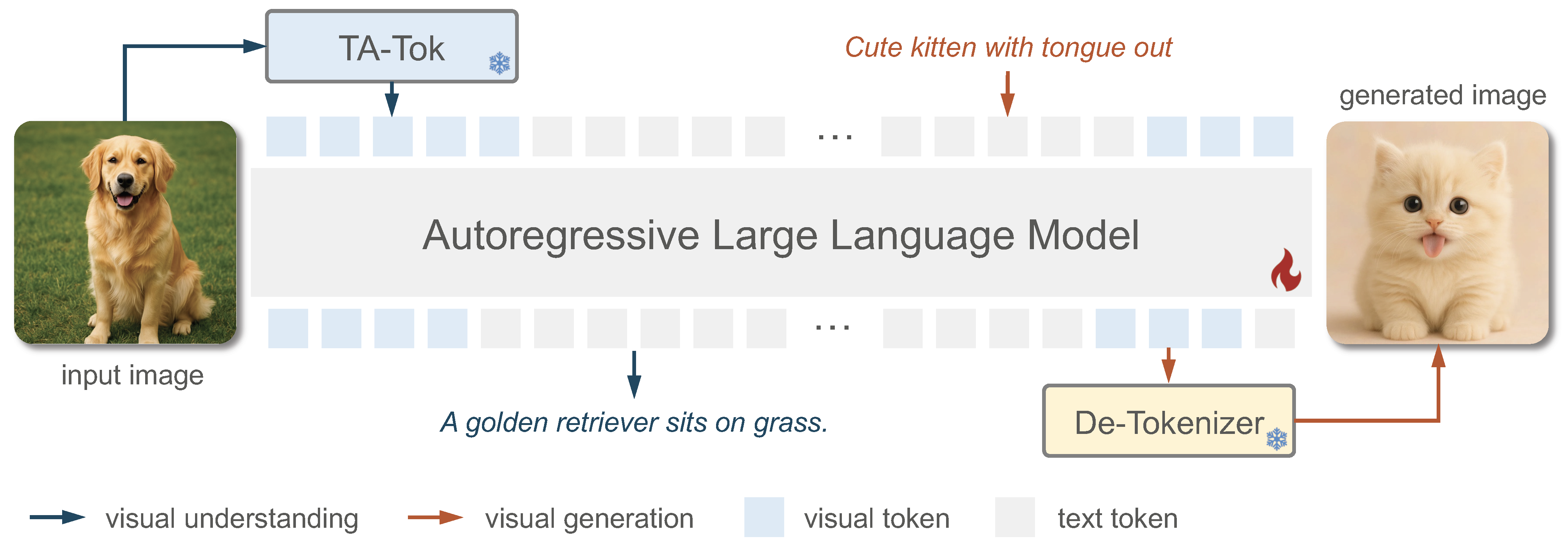
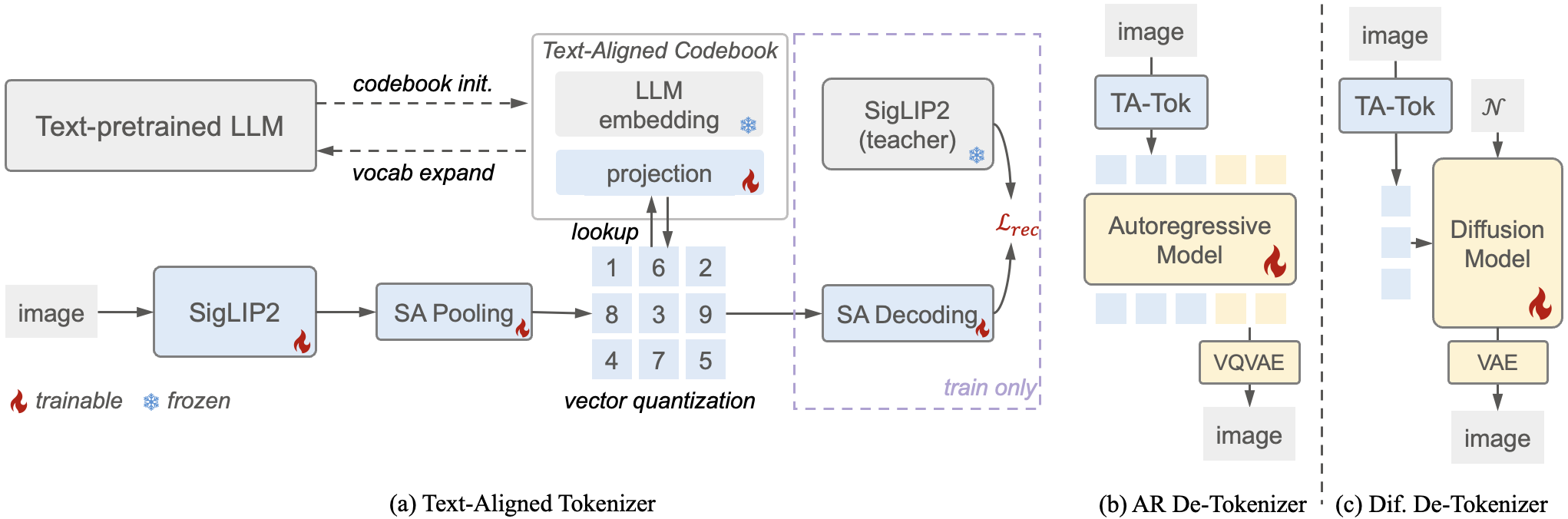
Results on Visual Understanding Benchmarks
* Token: Token type, including Continuous (C), Discrete (D), Semantic (S), Pixel (P) and Hybrid (H).
| Model | # LLM | Token | POPE↑ | MME-P↑ | MME-C↑ | MMB↑ | SEED↑ | GQA↑ | MMMU↑ |
|---|---|---|---|---|---|---|---|---|---|
| Show-o | 1.3B | D,P | 80.0 | 1097 | 248 | - | - | 58.0 | 26.7 |
| Harmon | 1.5B | C,H | 87.6 | 1155 | 321 | 65.5 | 67.1 | 58.9 | 38.9 |
| Janus | 1.5B | C,S | 87.0 | 1338 | 222 | 69.4 | 63.7 | 59.1 | 30.5 |
| Janus-Pro | 1.5B | C,S | 86.2 | 1444 | 268 | 75.5 | 68.3 | 59.3 | 36.3 |
| D-Dit | 2.0B | C,P | 84.0 | 1125 | - | - | - | 59.2 | - |
| Tar (Ours) | 1.5B | D,S | 88.4 | 1390 | 342 | 65.6 | 70.4 | 61.1 | 36.0 |
| ILLUME | 7B | C,S | 88.5 | 1445 | - | 65.1 | 72.9 | - | 38.2 |
| Chameleon | 7B | D,P | - | - | - | - | - | - | 22.4 |
| LWM | 7B | D,P | 75.2 | - | - | - | - | 44.8 | - |
| Liquid | 7B | D,P | 81.1 | 1119 | - | - | - | 58.4 | - |
| UniTok | 7B | D,H | 83.2 | 1448 | - | - | 61.1 | - | |
| VILA-U | 7B | D,H | 85.8 | 1402 | - | - | 59.0 | 60.8 | - |
| Janus-Pro | 7B | C,S | 87.4 | 1567 | 260 | 79.2 | 72.1 | 62.0 | 41.0 |
| MetaMorph | 8B | C,S | - | - | - | 75.2 | 71.8 | - | 41.8 |
| Tar (Ours) | 7B | D,S | 87.8 | 1571 | 355 | 74.4 | 73.0 | 61.3 | 39.0 |